很多企業的數據庫架構其實都在走向同一個問題:庫越來越多,鏈路越來越長,係統越來越重。
交易要上一套庫,分析要上一套庫,檢索要上一套庫,向量和知識庫又是一套。表麵看,各類需求都被滿足了;但從工程上看,代價也很直接: 數據要反複同步,接口要分別適配,運維要分頭處理,最後形成一個誰都離不開、誰都不好改的“多庫並存”體係。
這就是今天很多企業正在麵對的架構內耗。

所以,討論“融合數據庫”,不能停留在“一庫打天下”這種粗糙的理解上。真正的融合,不是拿一個庫去替掉世界上所有專用數據庫,也不是把幾種能力塞進同一個產品包裝裏。它要解決的,是企業已經被拆散的數據能力,能不能重新回到一個統一底座上。
什麽是真正的融合數據庫

融合數據庫的重點不是新增幾個功能點,而是把數據模型、執行引擎、部署架構、開發運維和AI能力重新組織成一個體係。
從91视频免费观看上看,融合數據庫至少有三個判斷標準。
第一,不是多組件拚裝,而是統一內核。
這是“融合”和“組合”最本質的區別。如果關係、時序、圖、向量、分析能力背後仍然是幾套獨立引擎,那數據同步、事務邊界、查詢協調、權限治理這些老問題一個都不會少。對用戶來說,隻是把原來的“多產品采購”,換成了“單產品打包”。
真正的融合型數據庫,必須建立在統一內核之上。也就是說,多種數據模型、多類處理能力,不是外掛組件,也不是旁路係統,而是在同一底層架構裏原生協同。這一點決定了融合到底是“工程能力”,還是“市場說法”。

第二,不是多份副本流轉,而是單一數據副本上的協同處理。
過去企業最常見的做法,是把交易庫的數據抽到分析庫,再同步到檢索庫、知識庫或向量庫。這樣做不是不能用,但問題也很明顯:數據有時差,鏈路會變長,治理會變散。
融合數據庫的價值,就在於盡量把這件事往回收。核心業務數據不再在多個係統之間反複搬運,而是盡可能在單一數據副本上完成多模型查詢、多負載處理和智能檢索。這樣做的意義,不隻是省幾套軟件,而是把實時性、一致性和治理複雜度一起拉回來。
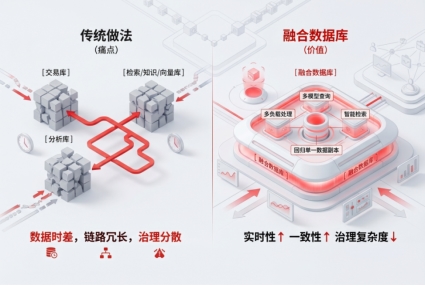
第三,不是單點能力堆疊,而是多模型、多負載的原生協同。
今天企業麵對的業務,已經不是單一關係模型就能覆蓋的。文檔、時序、圖、向量,都在進入一線業務流程;OLTP、OLAP、HTAP、語義檢索、RAG支撐,也不再是完全分開的幾條線。
如果數據庫隻能“分別支持”,那本質上還是各幹各的。真正的融合,應該是這些能力能在同一套體係裏協同工作。
以多模為例,關鍵不在於“能不能存文檔、向量、圖”,而在於能不能統一管理、統一索引、統一查詢,必要時還能用一條SQL把多種數據關聯起來,實現複雜檢索。
以多負載為例,關鍵不在於“既能做交易也能做分析”,而在於能不能在保證 OLTP 高並發、低時延的同時,支撐 OLAP 的高吞吐分析,並通過負載隔離避免相互爭搶資源。否則,所謂 HTAP 很容易退化成“誰忙誰拖慢全場”。
融合數據庫需要補齊的關鍵能力
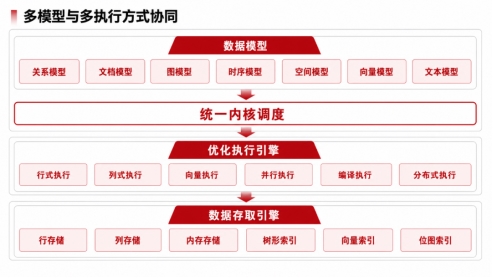
融合的91视频免费观看內涵,不是把關係、文檔、圖、向量簡單並列,而是讓多模型與多執行方式在同一架構內協同。
如果把這個邏輯再往下拆,融合數據庫在工程實現上通常還要補齊幾件事。
一是語法和生態兼容。企業不可能因為數據庫升級就重寫係統,所以兼容 Oracle、MySQL、PostgreSQL、SQL Server 等主流生態,本質上不是“錦上添花”,而是決定能不能平滑落地的前提。
二是部署架構統一。單實例、主備、讀寫分離、共享存儲集群、分布式、存算分離、跨中心多活,這些不是不同產品線的問題,而是同一底座對不同場景的適配能力。
三是開發運維一體化。融合如果隻停留在數據和執行層,效果還是不完整。開發、遷移、監控、巡檢、診斷、調優、自治運維,必須一起收進來,否則能力越多,維護麵越大。
四是 AI 與數據庫雙向融合。這裏有兩個方向。一個方向是 DB for AI,讓數據庫更好地支撐向量檢索、語義查詢、RAG 等智能應用;另一個方向是 AI for DB,讓 AI 參與 SQL 生成、異常診斷、性能調優和運維自治。前者決定數據庫能不能接住 AI 業務,後者決定數據庫自己能不能更高效地運行。
不是能力做加法,而是底座做減法
這也是為什麽說,融合數據庫的重點不是“多”,而是“通”。語法要通,數據要通,負載要通,架構要通,運維要通,AI 能力也要通。隻有這些層麵都打通,融合才不是一句口號。
從用戶價值看,這套邏輯最後會落到四個結果上:曆史應用可以平滑遷移,多種業務場景可以統一承載,多模數據可以統一處理,開發運維可以統一管理。說得更直接一點,就是少幾套庫、少幾條鏈路、少幾輪同步、少幾套治理體係。

用戶最終感知到的,不是“融合”這個詞本身,而是遷移成本、架構複雜度和運維負擔是否真正下降。
所以,融合數據庫的91视频免费观看內涵,歸根到底不是“能力做加法”,而是“底座做減法”。它不是把數據庫做得越來越像一個大雜燴,而是把原本分散、重複、割裂的數據能力重新收攏,變成一個可協同、可治理、可支撐 AI 業務的數據基礎設施。
這件事比做一個新功能難得多,因為它改的是底層邏輯,不是表層接口。但數據庫下一階段真正的競爭,也恰恰在這裏。誰能先把“多庫並存”的內耗降下來,誰才更有機會成為 AI 時代的新底座。
星空人工智能91视频免费观看網 倡導尊重與保護知識產權。如發現本站文章存在版權等問題,煩請30天內提供版權疑問、身份證明、版權證明、聯係方式等發郵件至1851688011@qq.com91视频免费播放將及時溝通與處理。!:首頁 > 大數據 » 從“多庫並立”到“一統底座”,AI時代數據庫必須收攏